SQL数据库分库分表下如何实现分页查询功能
当前位置:点晴教程→知识管理交流
→『 技术文档交流 』
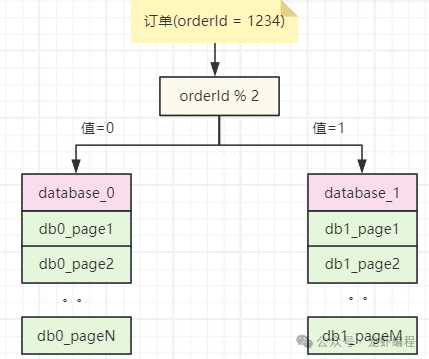
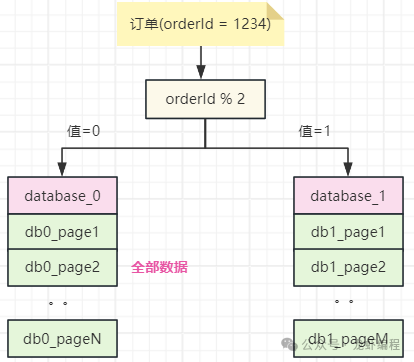
随着互联网的飞速发展,大公司的业务数据也爆发式增长。由于业务数据不断的增加,数据库的压力也是越来越大,单表数量上亿条也是很常见的常见,如订单数据、物流数据。为了应对这些大数据量的场景,常见的解决方案是分库分表,即就是将数据分散存储到不同的库或表中来有效地提高数据库的读写性能,从而实现更好地支撑实际的公司业务。 分库分表虽然可以解决单表数量过大的问题,同时它也带来了新的问题,典型的如业务数据的分页查询,下面我们分析数据水平切分下的分页查询实现的方案。 1、分库分表下分页查询问题的根源 假设现在采用通过订单id取模的策略将订单数据分布到两个不同的库(database_0与database_1)上,如下图所示:
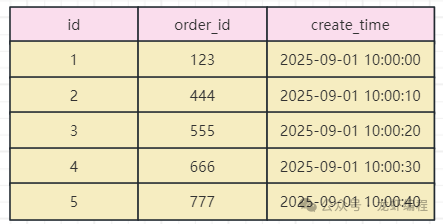
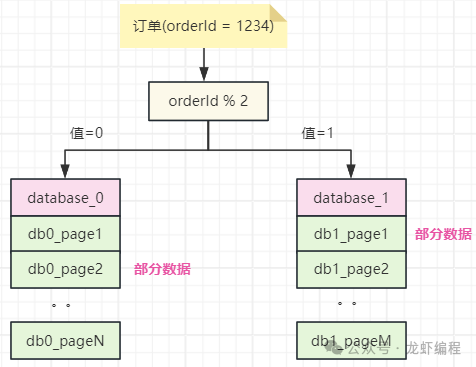
通过上述的操作之后,每个数据库都失去了“全局视野”,如下图所示的单个表中的数据:
在单表下,假设需求是每页展示3条数据,然后我们查询第2页的数据时,我们通过简单的sql查询就可以实现,sql如下所示:
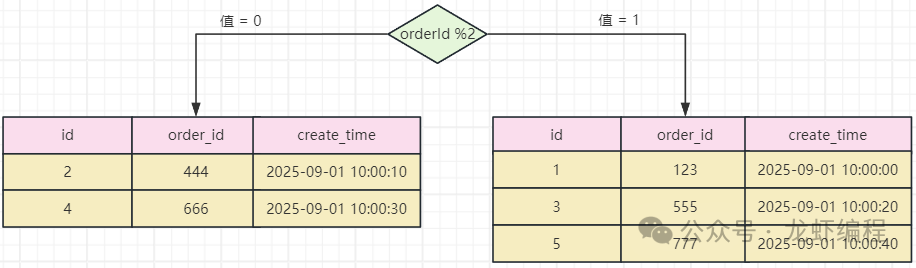
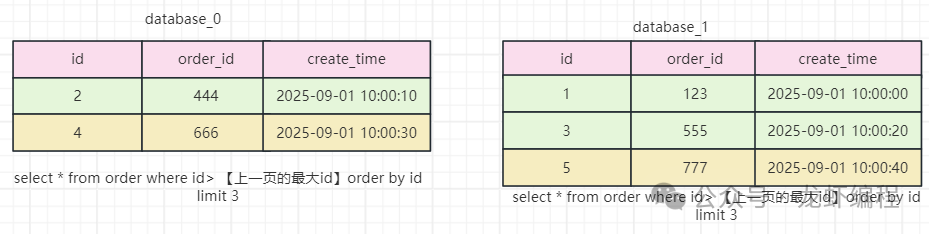
此时我们就可以查询到第2页的数据是id=4和id=5的数据。但是通过id取模之后数据分布在不同的库中,如下所示:
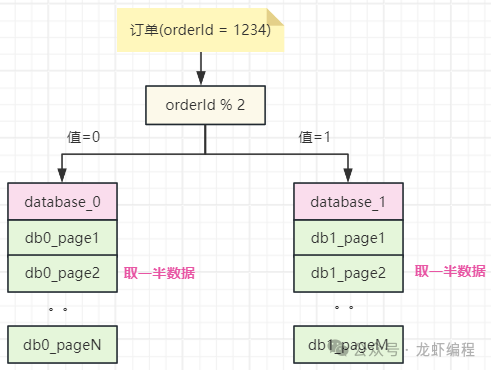
这个时候id=4和id=5的数据分布在不同的库上,此时如果每一个库上都通过select * from order order by create_time asc limit 3,3 分页查询的话就得不到数据了,那么就出现了分库分表下的分页查询问题。 2、全局查询法 如果两个库的数据完全相同,此时只需要每个库各取一半后再取半页数据,最终就是我们想要的数据,如下图所示:
(2)查询的结果在同一个库中 两个库的数据分布不均衡,此时我们要查询的数据在分布某一个库中,如下图所示的:
(3)查询的结果在两个库中 两个库的数据分布相对均衡,此时我们要查询的数据在分布在两个库中,如下图所示的:
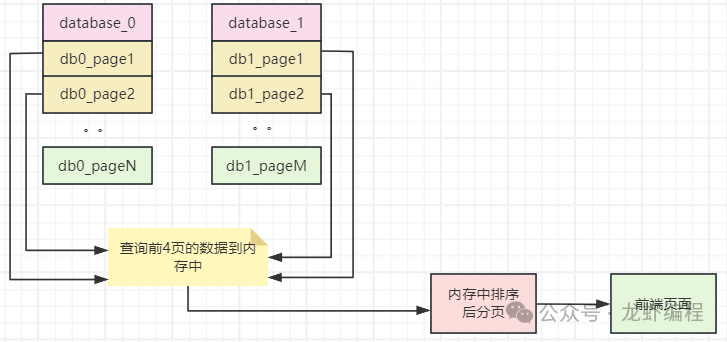
通过上述的分析得出分库分表下,我们要分页查询的数据由于不清楚到底是上述的哪种情况,所以在查询第2页数据的时候,我们必须要每个库都返回2页数据,这样得到的4页数据,然后在服务层进行内存排序,得到数据全局视野,再取第2页数据,便能够得到想要的全局分页数据,原理如下所示:
全局查询法方案优点: 通过服务层修改sql语句,扩大数据查询的范围进而能够得到全局视野数据,这样不仅业务数据全而且可以精准返回所需数据。 全局查询法方案缺点: 每个分库需要返回更多的数据,增大了网络传输量;数据查询到后需要服务层进行二次排序,增大了服务层的计算量。同时,随着查询翻页的页码增大,出现深度分页的问题。 3、全局查询法的优化方案——禁止跳页法 全局查询法虽然性能较差,但是其业务数据无损查询,数据精准,缺点是它的性能不稳定,随着翻页越深,性能越差。 市面上很多的产品中,他是不提供“直接跳到指定页面”的功能,而只提供“下一页”的功能,这一个小小的业务折衷,就能极大的降低技术方案的复杂度。我们页可以借鉴这种思想来优化全局查询法,假设现在不允许跳页,那么第一次只能够查第一页,分别在两个库中查询第一页的数据,然后记住第一页的最大id,查询第2页的时候带上第1页的最大id继续向后查询,如下图所示:
禁止跳页法可以有效的提升全局查询法的效率。 总结: (1)全局查询法可以实现业务数据无损查询,数据精准,但是存在深度分页的问题。 (2)业务允许的情况下我们可以使用禁止跳页法来优化全局查询法。 (3)可以借助ES等中间件来存储数据,从而实现更多的功能,但是也要注意ES的深度分页和数据同步的问题。 (4)使用ShardingSphere,它提供了一些内置的分页优化(如自动改写SQL+全局查找法+流式处理【排序,过滤)】) (5)如果业务允许的情况下,我们只提供“部分数据查询”,即就是展示一部分数据。 阅读原文:原文链接 该文章在 2025/11/10 15:07:03 编辑过 |
关键字查询
相关文章
正在查询... 



|


 400 186 1886
400 186 1886