网页两种乱码情况及其处理方式
当前位置:点晴教程→知识管理交流
→『 技术文档交流 』
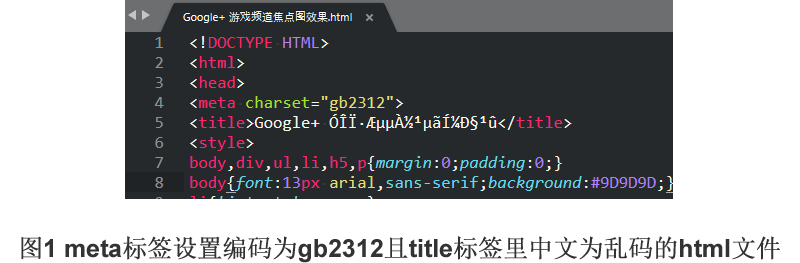
本文介绍两种导致乱码的情况,以及它们之间的联系和处理办法。 一、简介有一种乱码只是文件的打开方式不对而已,改用正确的方式打开乱码就会消失。 比如一个原本用gb2312编码的文件,你用默认设置了utf-8编码的编辑器打开,那么文件中的中文就都会以乱码形式呈现。 为啥只是中文乱码? 因为gb2312本质是ASCII码的超集,而ASCII码几乎包含了全部常用的英文字符,包括26个英文字母及其标点符号。所以即使用gb2312,英文也不会乱码。 这也是各种乱码文件中英文总是能正常显示,而其他的语言或者特殊字符总会不小心乱码的原因,因为ASCII码是各种常见编码的子集。 还有一种乱码则是在源码层面已经被错误编码了,乱码部分基本无法恢复,只能删掉重新编辑。 这里的重点在于,第二种情况常常是第一种情况下的错误操作导致的。 也就是本来只是重新设置下编辑器编码就能正常显示的文件,可能因为一个误操作被搞成永久性的乱码文件。 二、举例假设张三打开了一个html文件,发现文件里的中文都是乱码,又看到meta标签设置的编码是gb2312。 这时的张三可能暗自思忖,别人都是用utf-8就你用gb2312,难怪你是乱码。于是自作聪明直接把meta标签的gb2312改成了utf-8。
张三在进行了上述操作后,保存文件,然后重启编辑器。他觉得自己是统一了编码,使用了“永远不会乱码的utf-8”,指望重新打开文件后乱码会消失。 而实际情况却是,不光乱码不会消失,它还变成永久的了,原本正常的文件变成了一个无法恢复的乱码文件。 这是因为在源码中通过命令设置的编码集,其影响的是编译后的代码或解释器的执行结果,而不会影响源码本身的编码。 而我们在编辑器中打开的源文件里看到的乱码,其本质是源码,其展示是基于编辑器的编码集,所以这时的编码设置应该在编辑器的相关操作界面中进行。 如果我们只是在乱码情况下改动了这个html文件的meta标签,那么当前文件则会依照编辑器的一般默认编码重新编码为utf-8的文件并保存,这也包括里面的中文乱码。 这也就是把原本只是在内存中的因为编码集不匹配导致的暂时性的乱码,保存落地到了磁盘上。在事实上丢弃了原本正常的中文,而保存了因为错误解码而产生的乱码。 三、处理办法在上文案例中,要消除源码中的乱码一定不能先动源码,而是要先将编辑器的编码也设置为gb2312,先让乱码消失。 也许有人会说那不行,因为他日常使用的多数文件和系统都是utf-8的,他不能为了这一个gb2312的文件改了编辑器编码,让其他的文件都乱码显示。 这其实也有办法,只需要让原本gb2312编码的文件不再乱码之后,使用编辑器的转码功能将当前文件从gb2312转换为utf-8就行了。这时再将编辑器也还原为utf-8,就都可以正常显示了。 阅读原文:原文链接 该文章在 2025/8/25 13:32:35 编辑过 |
关键字查询
相关文章
正在查询... 



|


 400 186 1886
400 186 1886