在日常业务中经常会遇到上传大文件的需求(如上传一部3G大小的高清电影资源),如果大文件资源上传不做特殊处理而直接使用小文件上传的方式上传到服务,可能会出现如网络不好导致上传一半就失败了,服务内存不够导致无法上传等等一些问题。那么这个特殊处理是什么处理呢?其实就是大文件的分片上传。
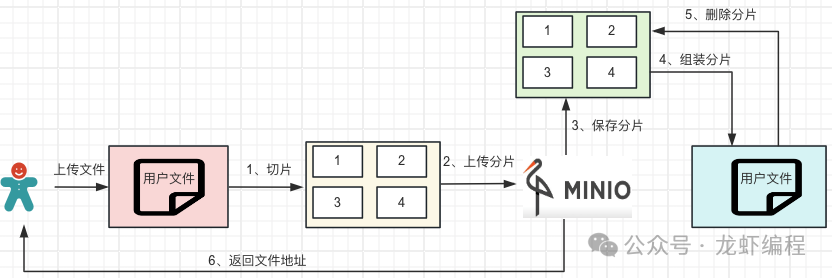
大文件分片上传需要前后端协作来完成,前端的工作是切片和生成文件的唯一标识;后端的工作是接收文件的唯一标识,记录文件上传的分片信息和整合分片成完整文件。下面设计一套前后端协作方式将大文件分片上传到MinIO上的方案。
1、生成文件的MD5值
前端需要唯一的标识一个文件,然后将唯一的标识传给后端做文件识别,那么用什么来唯一的标识一个文件呢?目前比较成熟的方案是将文件的二进制数据采用MD5映射成一个唯一标识。

MD5的一个很大特点是文件内容有变动(即使在文件内容中加了一个空格)就会生成一个新的唯一标识。因此采用MD5的方式给文件生成一个唯一的标识。
假设现在的文件有3G大小,那么计算其MD5值的时候直接将文件的内容的读取到内存中然后计算,此时内存可能会承受不了,所以采用分片的方式来计算MD5值。
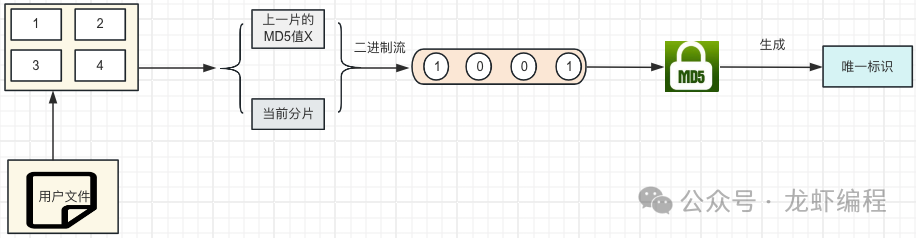
核心代码:
<template> <div> <input type="file" @change="onFileChange" /> <button @click="uploadFile">上传</button> </div></template><script> import SparkMD5 from 'spark-md5'; export default { data() { return { selectedFile: null, chunks: [], bytes: [], MD5Value: '', }; }, methods: { onFileChange(e) { this.selectedFile = e.target.files[0]; this.chunks = this.createChunks(this.selectedFile, 100 * 1024); //计算文件的hash this.calculateHash(this.chunks);
}, createChunks(file, chunkSize) { //文件切片 const result = []; for (let i = 0; i < file.size; i += chunkSize) { result.push(file.slice(i, i + chunkSize)) } return result; }, calculateHash(chunks) { //计算MD5值 const spark = new SparkMD5(); function readChunk(i) { if (i >= chunks.length) { this.MD5Value = spark.end(); console.info(this.MD5Value); return; } let blob = chunks[i]; const fileReader = new FileReader(); //异步获取文件的字节信息 fileReader.onload = e => { //获取到读取的字节数组 spark.append(e.target.result); readChunk(i + 1); }; //读文件的字节 fileReader.readAsArrayBuffer(blob) } readChunk(0); } } };</script>
如果文件过大的话,即使采用分片的方式计算文件的MD5值也是非常慢的,所以设计的时候可以使用一个进度条的方式让用户知道当前正在解析文件并且当前的解析进度是多少,如下设计的解析文件的进度图:
2、判断当前的文件上传信息
前端计算文件的MD5值后可以唯一标识这个文件,然后前端将MD5值传给后端,后端告诉前端当前的文件是否上传过
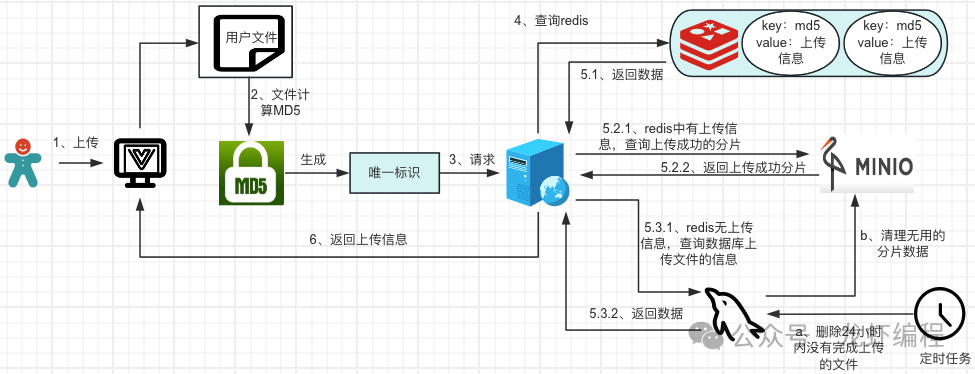
后端拿到MD5的值后到Redis中查询是否存在上传的记录信息:
(1)如果Redis中存在文件上传的信息,那么需要查询MinIO上已经上传成功的分片,计算未上传成功的分片信息,封装成对象返回给前端。
(2)如果Redis中没有数据的,查询数据库是否有文件的上传信息,数据库中要么文件已经完成上传并有文件在MinIO上的地址信息,要么就是没有上传(文件首次上传),结果封装成对象返回给前端。
核心代码:
/** * 检查当前文件的上传情况 * * @param md5 文件的md5标识 */public FileUploadInfo checkFileUploadByMd5(String md5) { //查询redis是否存在文件的上传信息 FileUploadInfo fileUploadInfo = RedisUtils.get(md5); //Redis中存在上传信息 if (Objects.nonNull(fileUploadInfo)) { //获取已经上传成功的分片信息 List<Integer> listParts = minioUtil.getListParts(fileUploadInfo.getObject(), fileUploadInfo.getUploadId()); fileUploadInfo.setListParts(listParts); return fileUploadInfo; } //查询数据库是否有上传记录 File file = filesMapper.selectUpdaLoadByMd5(md5); if (file != null) { //标识文件之前已经上传成功了,直接返回其在MinIO上的地址 FileUploadInfo dbFileInfo = BeanUtils.copyProperties(file, FileUploadInfo.class); return dbFileInfo; } return null; }
3、每个分片生成临时的凭证
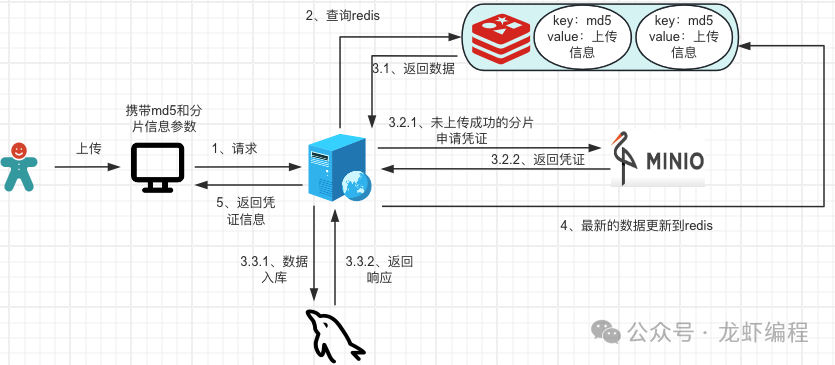
如果当前的文件是没有上传过或者断点上传的时候,需要携带md5和分片信息请求后端,后端根据MD5查询Redis中上传文件的信息来申请凭证,如果是断点续传情况,需要过滤已经上传成功的分片再去申请凭证;凭证通过后保存数据和更新Redis,然后返回凭证信息、uploadId给前端。
核心的代码:
//文件分片申请凭证信息 public UploadUrlsVO multipartFileUpload(FileUploadInfo fileUploadInfo) { UploadUrlsVO uploadUrlsVO; String filePath; //查询Redis是否存在上传信息 FileUploadInfo redisFileUploadInfo = RedisUtils.get(fileUploadInfo.getMd5()); //redis存在上传信息 if (Objects.nonNull(redisFileUploadInfo)) { fileUploadInfo = redisFileUploadInfo; filePath = redisFileUploadInfo.getObject(); } else { //redis中无上传信息 //文件原始名称 String originName = fileUploadInfo.getOriginFileName(); filePath = DateUtil.format(LocalDateTime.now(), "yyyy/MM/dd") + "/" + FileUtil.mainName(originName) + "_" + fileUploadInfo.getMd5() + "." + FileUtil.extName(originName); fileUploadInfo.setObject(filePath).setType(suffix); } //未分片的文件上传 if (fileUploadInfo.getChunkCount() == 1) { uploadUrlsVO = minioUtil.uploadSingleFile(fileUploadInfo.getContentType(), filePath); } else { // 分片上传 uploadUrlsVO = minioUtil.multiPartFileUpload(fileUploadInfo, filePath); } fileUploadInfo.setUploadId(urlsVO.getUploadId()); //最新的分片信息存到redis RedisUtils.set(fileUploadInfo.getMd5(), fileUploadInfo, minioConfigInfo.getBreakpointTime(), TimeUnit.DAYS); return uploadUrlsVO; }
4、前端上传分片和请求后端合并文件
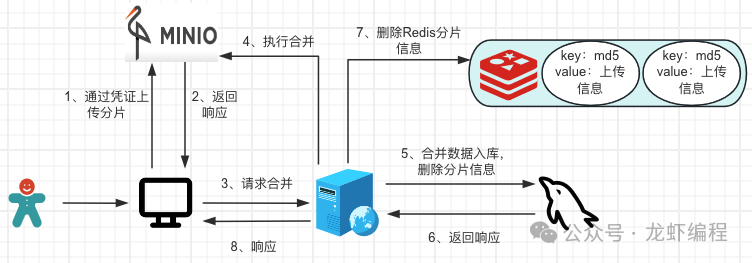
前端通过后端的凭证开始上传分片信息,分片上传完成之后请求后端将分片的合并成一个完整的文件,然后获取到完成的文件地址保存到数据库。
核心代码:
@Overridepublic String mergeMultipartUpload(String md5) { //获取Redis中上传文件的信息 FileUploadInfo redisFileUploadInfo = RedisUtils.get(md5); String fileUrl = StrUtil.format("{}/{}/{}", minioConfigInfo.getEndpoint(), minioConfigInfo.getBucket(), redisFileUploadInfo.getObject()); //组装数据库实体 Files file = BeanUtils.copyProperties(redisFileUploadInfo, Files.class); file.setUrl(fileUrl); file.setBucket(minioConfigInfo.getBucket()); //分片为1时不需要合并,否则合并 if (redisFileUploadInfo.getChunkCount() == 1 || minioUtil.mergeMultipartFile(redisFileUploadInfo.getObject(), redisFileUploadInfo.getUploadId())) { filesMapper.insertFile(file); //删除Redis中分片的信息 redisUtil.del(md5); return fileUrl; } //抛出异常提示 throw new BussinessException(); }
总结:
(1)文件分片上传需要前端生成文件的唯一标识和分片。
(2)后端根据唯一标识判断是否存在上传信息,如果存在就判断是上传完成还是断点上传,如果上传完整直接返回Minio上文件的地址,如果是断点上传就返回哪些分片已经上传成功的信息给前端。
(3)前端过滤上传成功的分片,将未上传成功的分片请求后端申请凭证,申请成功之后上传分片,上传完成就请求后端合并分片成完成的文件并保存文件的地址到数据库,删除分片记录。
(4)秒传是因为之前这个文件已经上传过,数据库中已经存储了文件在MinIO上完整的地址。
(5)断点续传的原理是记录已经完成上传的分片,再次上传的时候这些分片无需再次上传,只上传未完成上传的分片。
该文章在 2024/6/8 22:51:46 编辑过






 400 186 1886
400 186 1886


