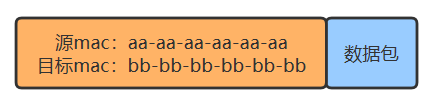一文看懂计算机网络设计原理
当前位置:点晴教程→知识管理交流
→『 技术文档交流 』
很久很久之前,你不与任何其他电脑相连接,孤苦伶仃。
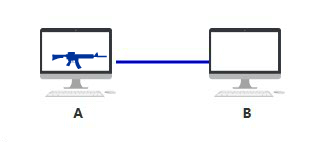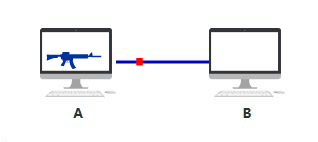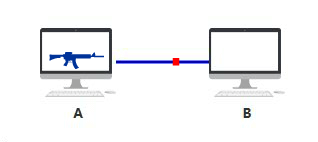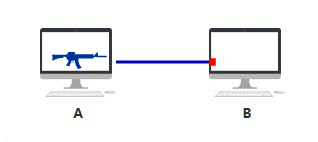
直到有一天,你希望与另一台电脑 B 建立通信,于是你们各开了一个网口,用一根网线连接了起来。
用一根网线连接起来怎么就能"通信"了呢?我可以给你讲 IO、讲中断、讲缓冲区,但这不是研究网络时该关心的问题。 如果你纠结,要么去研究一下操作系统是如何处理网络 IO 的,要么去研究一下包是如何被网卡转换成电信号发送出去的,要么就仅仅把它当做电脑里有个小人在开枪吧~
反正,你们就是连起来了,并且可以通信。 第一层
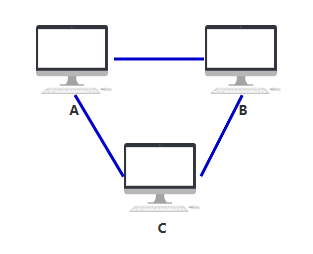
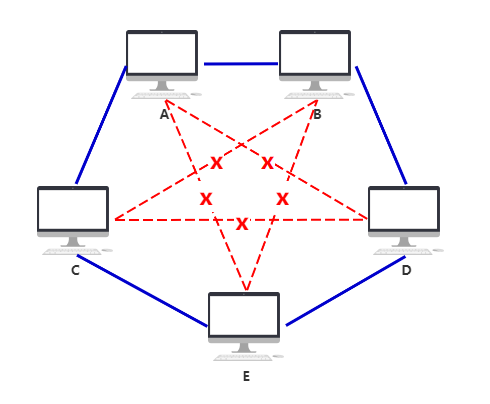
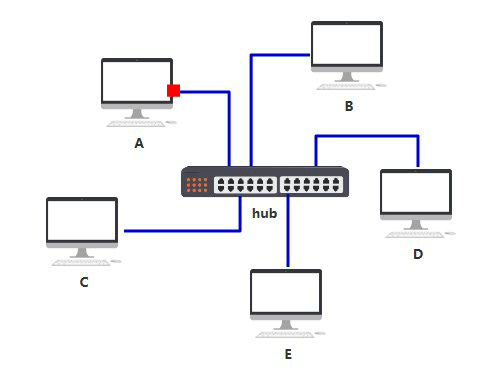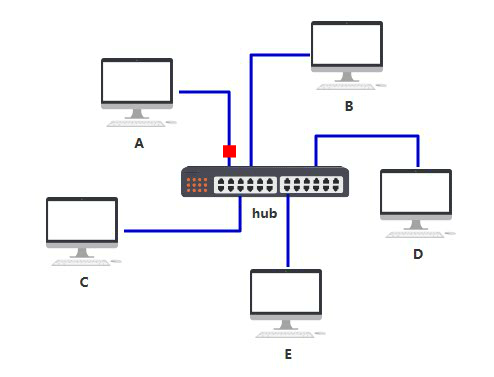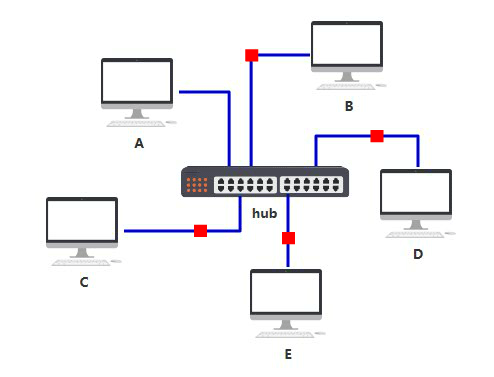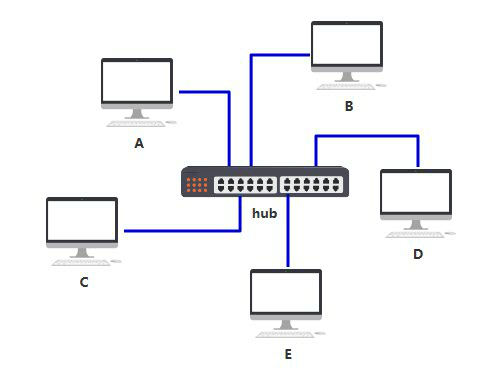
随着越来越多的人加入,你发现身上开的网口实在太多了,而且网线密密麻麻,混乱不堪。(而实际上一台电脑根本开不了这么多网口,所以这种连线只在理论上可行,所以连不上的我就用红色虚线表示了,就是这么严谨哈哈~)
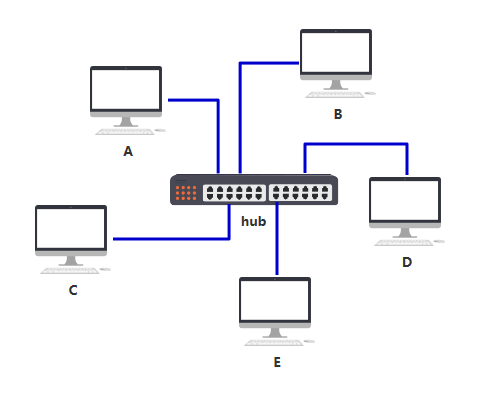
于是你们发明了一个中间设备,你们将网线都插到这个设备上,由这个设备做转发,就可以彼此之间通信了,本质上和原来一样,只不过网口的数量和网线的数量减少了,不再那么混乱。
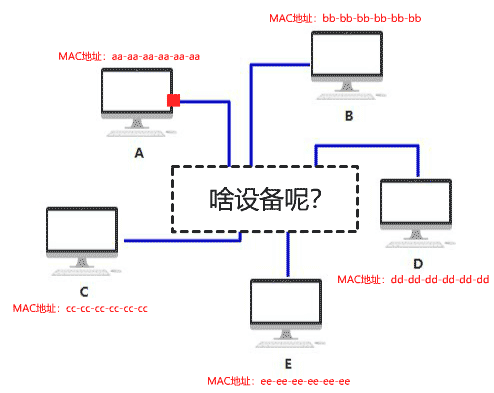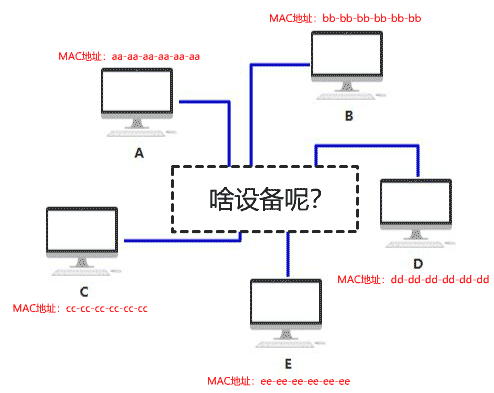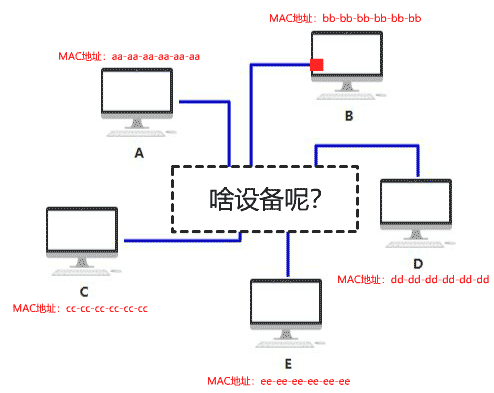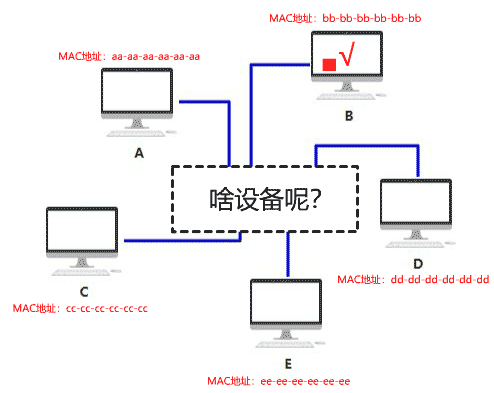
你给它取名叫集线器,它仅仅是无脑将电信号转发到所有出口(广播),不做任何处理,你觉得它是没有智商的,因此把人家定性在了物理层。
由于转发到了所有出口,那 BCDE 四台机器怎么知道数据包是不是发给自己的呢? 首先,你要给所有的连接到集线器的设备,都起个名字。原来你们叫 ABCD,但现在需要一个更专业的,全局唯一的名字作为标识,你把这个更高端的名字称为 MAC 地址。 你的 MAC 地址是 aa-aa-aa-aa-aa-aa,你的伙伴 b 的 MAC 地址是 bb-bb-bb-bb-bb-bb,以此类推,不重复就好。 这样,A 在发送数据包给 B 时,只要在头部拼接一个这样结构的数据,就可以了。
B 在收到数据包后,根据头部的目标 MAC 地址信息,判断这个数据包的确是发给自己的,于是便收下。 其他的 CDE 收到数据包后,根据头部的目标 MAC 地址信息,判断这个数据包并不是发给自己的,于是便丢弃。
虽然集线器使整个布局干净不少,但原来我只要发给电脑 B 的消息,现在却要发给连接到集线器中的所有电脑,这样既不安全,又不节省网络资源。 第二层 如果把这个集线器弄得更智能一些,只发给目标 MAC 地址指向的那台电脑,就好了。
虽然只比集线器多了这一点点区别,但看起来似乎有智能了,你把这东西叫做交换机。也正因为这一点点智能,你把它放在了另一个层级,数据链路层。
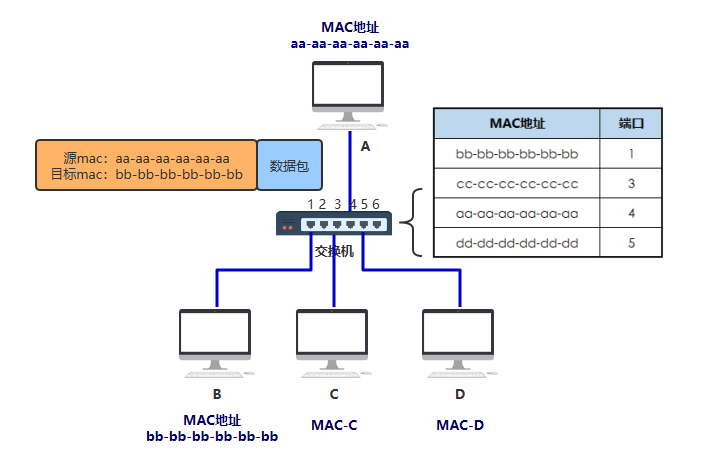
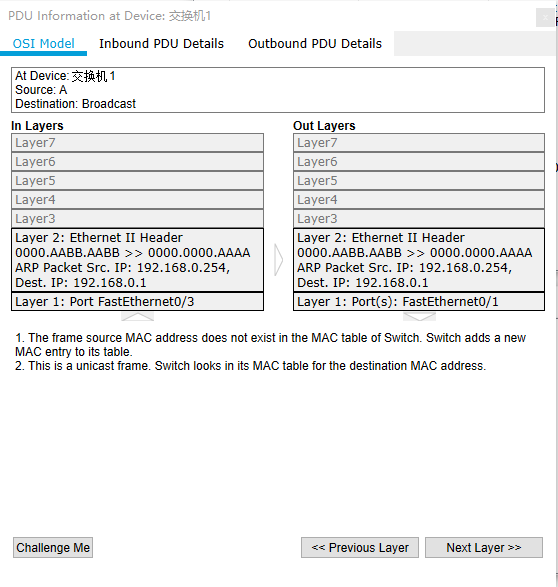
如上图所示,你是这样设计的。 交换机内部维护一张 MAC 地址表,记录着每一个 MAC 地址的设备,连接在其哪一个端口上。
假如你仍然要发给 B 一个数据包,构造了如下的数据结构从网口出去。
到达交换机时,交换机内部通过自己维护的 MAC 地址表,发现目标机器 B 的 MAC 地址 bb-bb-bb-bb-bb-bb 映射到了端口 1 上,于是把数据从 1 号端口发给了 B,完事~ 你给这个通过这样传输方式而组成的小范围的网络,叫做以太网。 当然最开始的时候,MAC 地址表是空的,是怎么逐步建立起来的呢? 假如在 MAC 地址表为空是,你给 B 发送了如下数据
由于这个包从端口 4 进入的交换机,所以此时交换机就可以在 MAC地址表记录第一条数据: MAC:aa-aa-aa-aa-aa-aa-aa 交换机看目标 MAC 地址(bb-bb-bb-bb-bb-bb)在地址表中并没有映射关系,于是将此包发给了所有端口,也即发给了所有机器。 之后,只有机器 B 收到了确实是发给自己的包,于是做出了响应,响应数据从端口 1 进入交换机,于是交换机此时在地址表中更新了第二条数据: MAC:bb-bb-bb-bb-bb-bb 过程如下
经过该网络中的机器不断地通信,交换机最终将 MAC 地址表建立完毕~
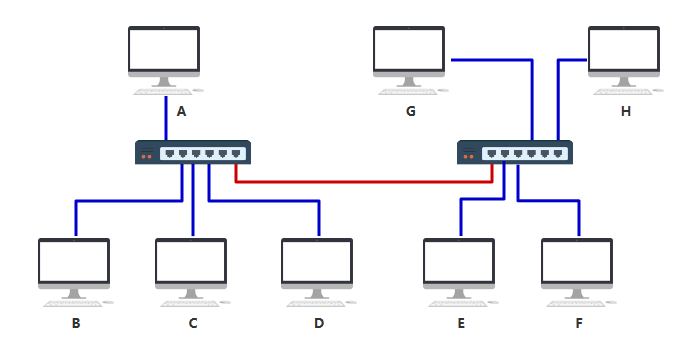
随着机器数量越多,交换机的端口也不够了,但聪明的你发现,只要将多个交换机连接起来,这个问题就轻而易举搞定~
你完全不需要设计额外的东西,只需要按照之前的设计和规矩来,按照上述的接线方式即可完成所有电脑的互联,所以交换机设计的这种规则,真的很巧妙。你想想看为什么(比如 A 要发数据给 F)。 但是你要注意,上面那根红色的线,最终在 MAC 地址表中可不是一条记录呀,而是要把 EFGH 这四台机器与该端口(端口6)的映射全部记录在表中。 最终,两个交换机将分别记录 A ~ H 所有机器的映射记录。 左边的交换机
右边的交换机
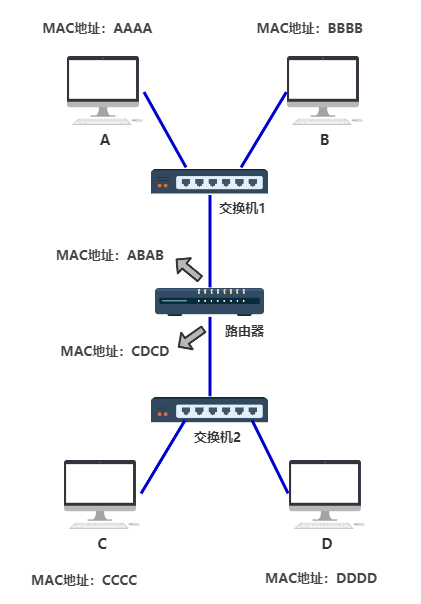
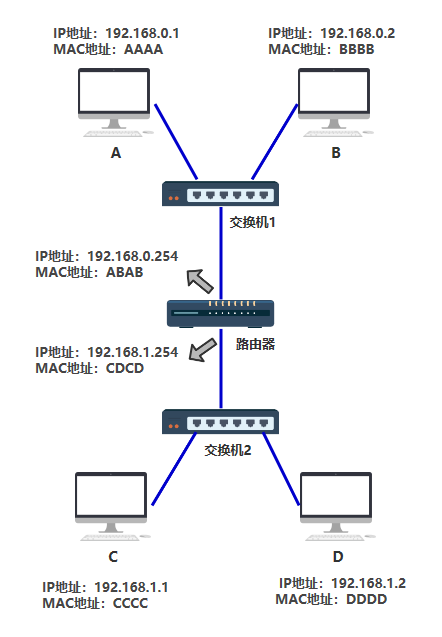
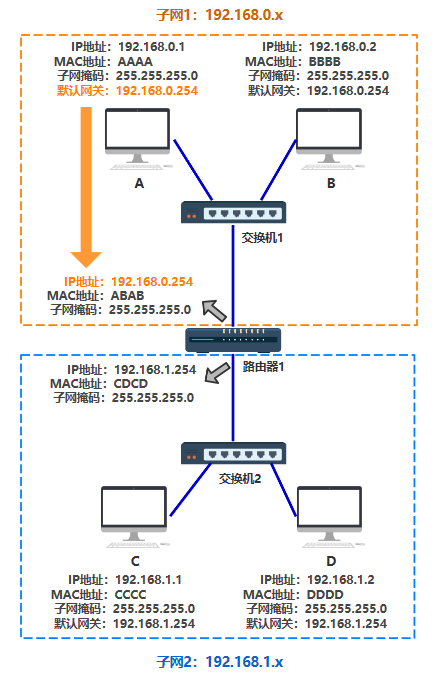
这在只有 8 台电脑的时候还好,甚至在只有几百台电脑的时候,都还好,所以这种交换机的设计方式,已经足足支撑一阵子了。 但很遗憾,人是贪婪的动物,很快,电脑的数量就发展到几千、几万、几十万。 第三层 交换机已经无法记录如此庞大的映射关系了。 此时你动了歪脑筋,你发现了问题的根本在于,连出去的那根红色的网线,后面不知道有多少个设备不断地连接进来,从而使得地址表越来越大。 那我可不可以让那根红色的网线,接入一个新的设备,这个设备就跟电脑一样有自己独立的 MAC 地址,而且同时还能帮我把数据包做一次转发呢? 这个设备就是路由器,它的功能就是,作为一台独立的拥有 MAC 地址的设备,并且可以帮我把数据包做一次转发,你把它定在了网络层。
注意,路由器的每一个端口,都有独立的 MAC 地址 好了,现在交换机的 MAC 地址表中,只需要多出一条 MAC 地址 ABAB 与其端口的映射关系,就可以成功把数据包转交给路由器了,这条搞定。 那如何做到,把发送给 C 和 D,甚至是把发送给 DEFGH.... 的数据包,统统先发送给路由器呢? 不难想到这样一个点子,假如电脑 C 和 D 的 MAC 地址拥有共同的前缀,比如分别是 那我们就可以说,将目标 MAC 地址为 FFFF-FFFF-?开头的,统统先发送给路由器。 这样是否可行呢?答案是否定的。 我们先从现实中 MAC 地址的结构入手,MAC地址也叫物理地址、硬件地址,长度为 48 位,一般这样来表示 00-16-EA-AE-3C-40 它是由网络设备制造商生产时烧录在网卡的EPROM(一种闪存芯片,通常可以通过程序擦写)。其中前 24 位(00-16-EA)代表网络硬件制造商的编号,后 24 位(AE-3C-40)是该厂家自己分配的,一般表示系列号。只要不更改自己的 MAC 地址,MAC 地址在世界是唯一的。形象地说,MAC地址就如同身份证上的身份证号码,具有唯一性。 那如果你希望向上面那样表示将目标 MAC 地址为 FFFF-FFFF-?开头的,统一从路由器出去发给某一群设备(后面会提到这其实是子网的概念),那你就需要要求某一子网下统统买一个厂商制造的设备,要么你就需要要求厂商在生产网络设备烧录 MAC 地址时,提前按照你规划好的子网结构来定 MAC 地址,并且日后这个网络的结构都不能轻易改变。 这显然是不现实的。 于是你发明了一个新的地址,给每一台机器一个 32 位的编号,如: 11000000101010000000000000000001 你觉得有些不清晰,于是把它分成四个部分,中间用点相连。 11000000.10101000.00000000.00000001 你还觉得不清晰,于是把它转换成 10 进制。 192.168.0.1 最后你给了这个地址一个响亮的名字,IP 地址。现在每一台电脑,同时有自己的 MAC 地址,又有自己的 IP 地址,只不过 IP 地址是软件层面上的,可以随时修改,MAC 地址一般是无法修改的。 这样一个可以随时修改的 IP 地址,就可以根据你规划的网络拓扑结构,来调整了。
如上图所示,假如我想要发送数据包给 ABCD 其中一台设备,不论哪一台,我都可以这样描述,"将 IP 地址为 192.168.0 开头的全部发送给到路由器,之后再怎么转发,交给它!",巧妙吧。 那交给路由器之后,路由器又是怎么把数据包准确转发给指定设备的呢? 别急我们慢慢来。 我们先给上面的组网方式中的每一台设备,加上自己的 IP 地址
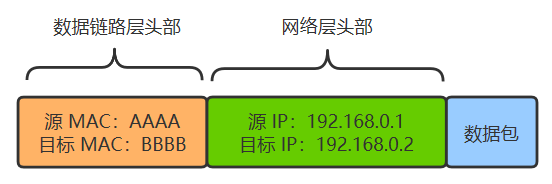
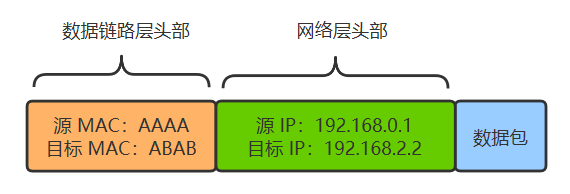
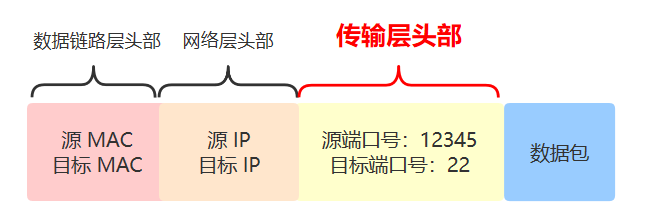
现在两个设备之间传输,除了加上数据链路层的头部之外,还要再增加一个网络层的头部。 假如 A 给 B 发送数据,由于它们直接连着交换机,所以 A 直接发出如下数据包即可,其实网络层没有体现出作用。
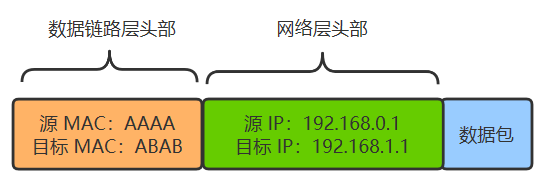
但假如 A 给 C 发送数据,A 就需要先转交给路由器,然后再由路由器转交给 C。由于最底层的传输仍然需要依赖以太网,所以数据包是分成两段的。 A ~ 路由器这段的包如下:
路由器到 C 这段的包如下:
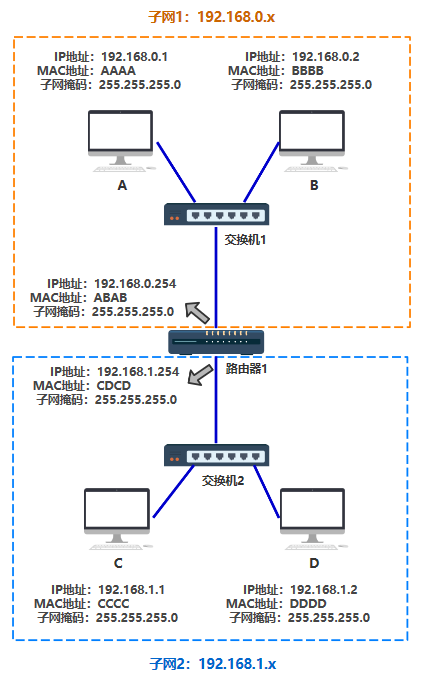
好了,上面说的两种情况(A->B,A->C),相信细心的读者应该会有不少疑问,下面我们一个个来展开。 A 给 C 发数据包,怎么知道是否要通过路由器转发呢? 答案:子网 如果源 IP 与目的 IP 处于一个子网,直接将包通过交换机发出去。 如果源 IP 与目的 IP 不处于一个子网,就交给路由器去处理。 好,那现在只需要解决,什么叫处于一个子网就好了。
这两个是我们人为规定的,即我们想表示,对于 192.168.0.1 来说: 192.168.0.xxx 开头的,就算是在一个子网,否则就是在不同的子网。 那对于计算机来说,怎么表达这个意思呢?于是人们发明了子网掩码的概念 假如某台机器的子网掩码定为 255.255.255.0 这表示,将源 IP 与目的 IP 分别同这个子网掩码进行与运算,相等则是在一个子网,不相等就是在不同子网,就这么简单。 比如
那么 A 与 B 在同一个子网,C 与 D 在同一个子网,但是 A 与 C 就不在同一个子网,与 D 也不在同一个子网,以此类推。
所以如果 A 给 C 发消息,A 和 C 的 IP 地址分别 & A 机器配置的子网掩码,发现不相等,则 A 认为 C 和自己不在同一个子网,于是把包发给路由器,就不管了,之后怎么转发,A 不关心。 A 如何知道,哪个设备是路由器? 答案:在 A 上要设置默认网关 上一步 A 通过是否与 C 在同一个子网内,判断出自己应该把包发给路由器,那路由器的 IP 是多少呢? 其实说发给路由器不准确,应该说 A 会把包发给默认网关。 对 A 来说,A 只能直接把包发给同处于一个子网下的某个 IP 上,所以发给路由器还是发给某个电脑,对 A 来说也不关心,只要这个设备有个 IP 地址就行。 所以默认网关,就是 A 在自己电脑里配置的一个 IP 地址,以便在发给不同子网的机器时,发给这个 IP 地址。
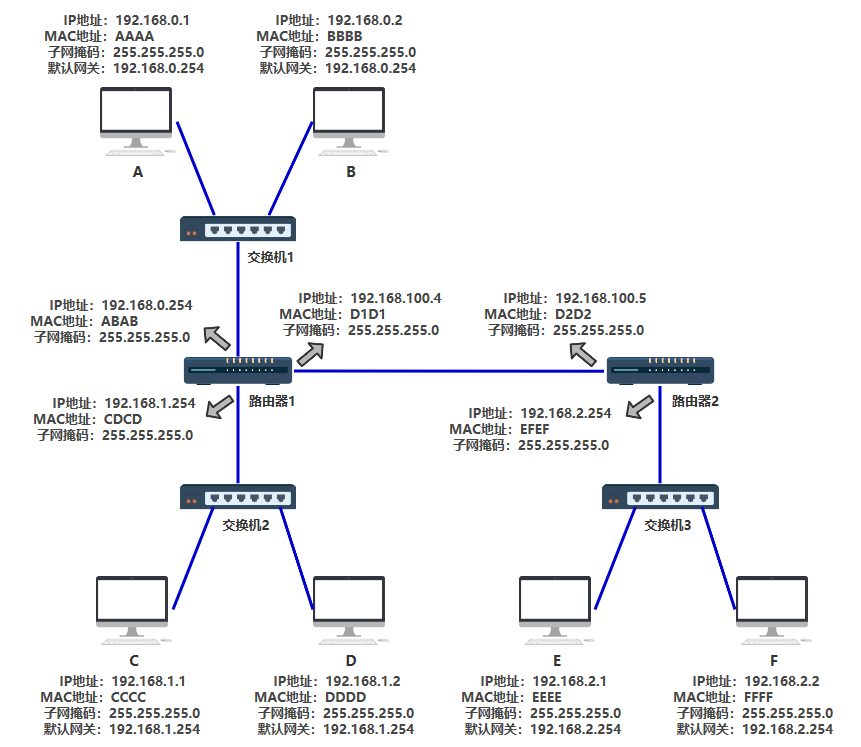
仅此而已! 路由器如何知道C在哪里? 答案:路由表 现在 A 要给 C 发数据包,已经可以成功发到路由器这里了,最后一个问题就是,路由器怎么知道,收到的这个数据包,该从自己的哪个端口出去,才能直接(或间接)地最终到达目的地 C 呢。 路由器收到的数据包有目的 IP 也就是 C 的 IP 地址,需要转化成从自己的哪个端口出去,很容易想到,应该有个表,就像 MAC 地址表一样。 这个表就叫路由表。 至于这个路由表是怎么出来的,有很多路由算法,本文不展开,因为我也不会哈哈~ 不同于 MAC 地址表的是,路由表并不是一对一这种明确关系,我们下面看一个路由表的结构。
我们学习一种新的表示方法,由于子网掩码其实就表示前多少位表示子网的网段,所以如 192.168.0.0(255.255.255.0) 也可以简写为 192.168.0.0/24
这就很好理解了,路由表就表示,192.168.0.xxx 这个子网下的,都转发到 0 号端口,192.168.1.xxx 这个子网下的,都转发到 1 号端口。下一跳列还没有值,我们先不管 配合着结构图来看(这里把子网掩码和默认网关都补齐了)图中 & 笔误,结果应该是 .0
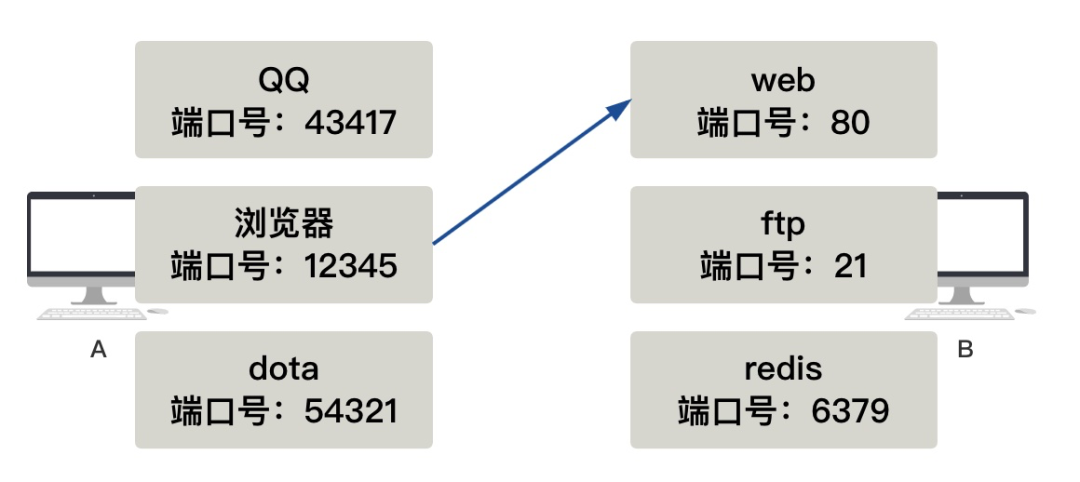
刚才说的都是 IP 层,但发送数据包的数据链路层需要知道 MAC 地址,可是我只知道 IP 地址该怎么办呢? 答案:arp 假如你(A)此时不知道你同伴 B 的 MAC 地址(现实中就是不知道的,刚刚我们只是假设已知),你只知道它的 IP 地址,你该怎么把数据包准确传给 B 呢? 答案很简单,在网络层,我需要把 IP 地址对应的 MAC 地址找到,也就是通过某种方式,找到 192.168.0.2 对应的 MAC 地址 BBBB。 这种方式就是 arp 协议,同时电脑 A 和 B 里面也会有一张 arp 缓存表,表中记录着 IP 与 MAC 地址的对应关系。
一开始的时候这个表是空的,电脑 A 为了知道电脑 B(192.168.0.2)的 MAC 地址,将会广播一条 arp 请求,B 收到请求后,带上自己的 MAC 地址给 A 一个响应。此时 A 便更新了自己的 arp 表。 这样通过大家不断广播 arp 请求,最终所有电脑里面都将 arp 缓存表更新完整。 总结一下 好了,总结一下,到目前为止就几条规则 从各个节点的视角来看 电脑视角:
交换机视角:
路由器视角:
如果你嗅觉足够敏锐,你应该可以感受到下面这句话: 网络层(IP协议)本身没有传输包的功能,包的实际传输是委托给数据链路层(以太网中的交换机)来实现的。 涉及到的三张表分别是
这三张表是怎么来的
知道了以上这些,目前网络上两个节点是如何发送数据包的这个过程,就完全可以解释通了!
那接下来我们 趁热打铁 一下,请做好 战斗 准备!
这时路由器 1 连接了路由器 2,所以其路由表有了下一条地址这一个概念,所以它的路由表就变成了这个样子。如果匹配到了有下一跳地址的一项,则需要再次匹配,找到其端口,并找到下一跳 IP 的 MAC 地址。 也就是说找来找去,最终必须能映射到一个端口号,然后从这个端口号把数据包发出去。
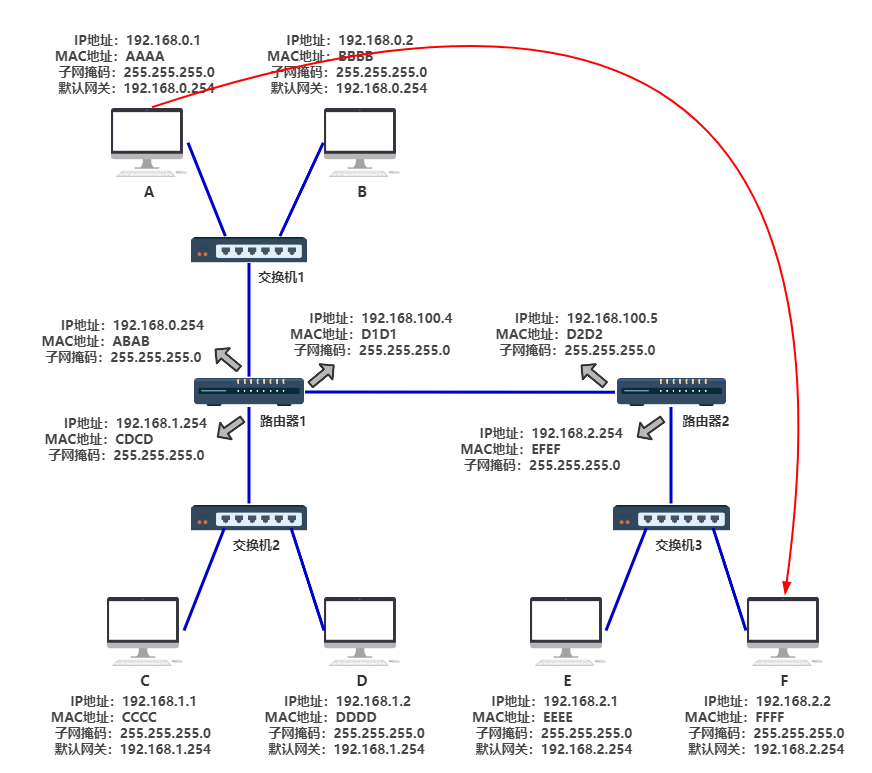
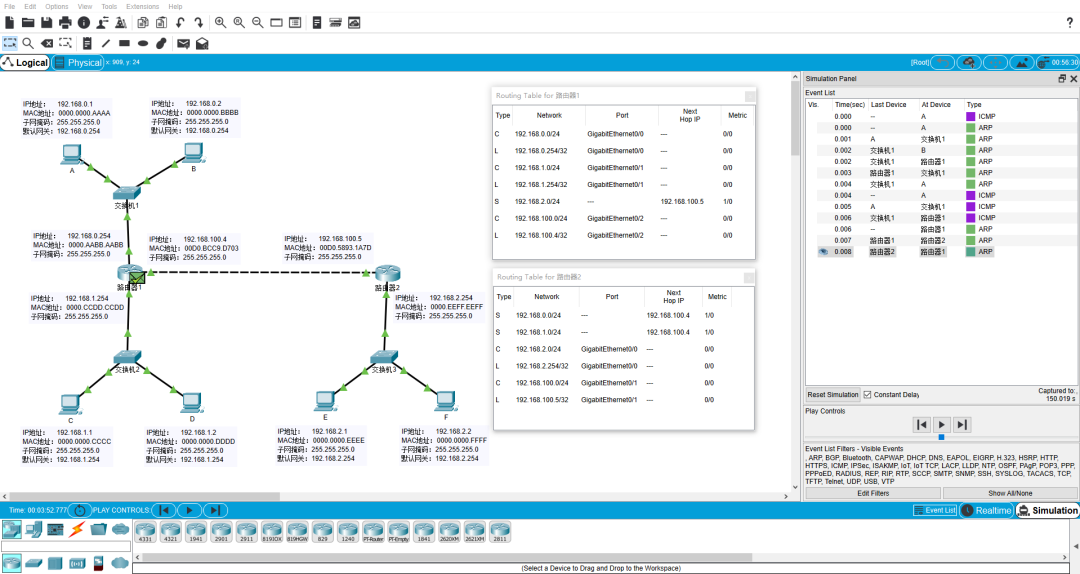
这时如果 A 给 F 发送一个数据包,能不能通呢?如果通的话整个过程是怎样的呢?
思考一分钟... 详细过程动画描述:
详细过程文字描述:
读到这相信大家已经很累了,理解上述过程基本上网络层以下的部分主流程就基本疏通了,如果你想要本过程更为专业的过程描述,可以在公众号"无聊的闪客"后台回复"网络",获得我模拟这个过程的 Cisco Packet Tracer 源文件。
每一步包的传输都会有各层的原始数据,以及专业的过程描述
同时在此基础之上你也可以设计自己的网络拓扑结构,进行各种实验,来加深网络传输过程的理解。 你是不是以为到这里就结束了? 不,好戏才刚刚开始! 请休息一分钟,我们继续战斗!
问题来了
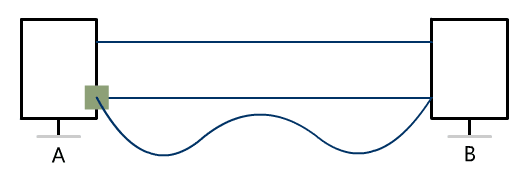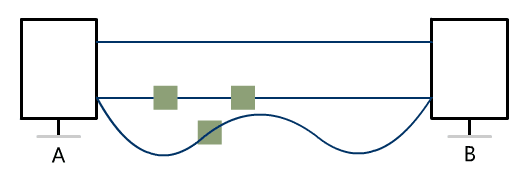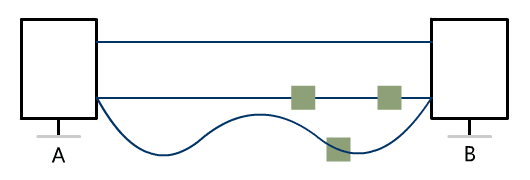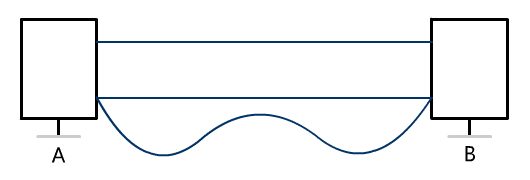
丢包问题
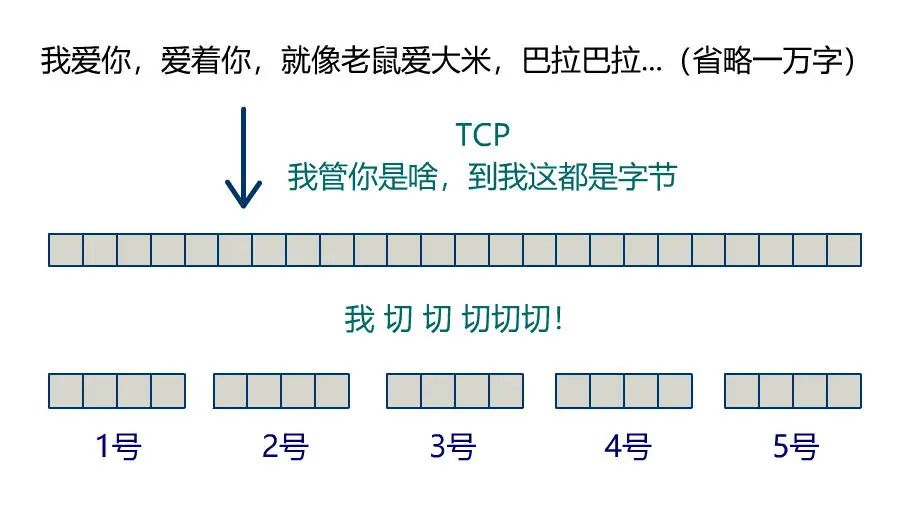
效率问题
顺序问题
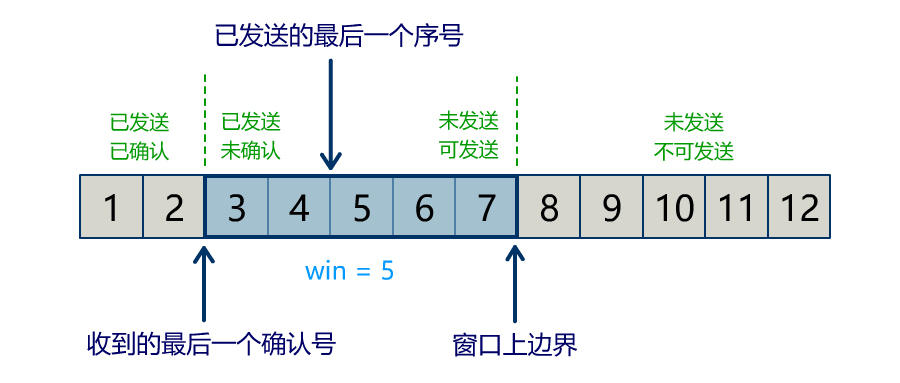
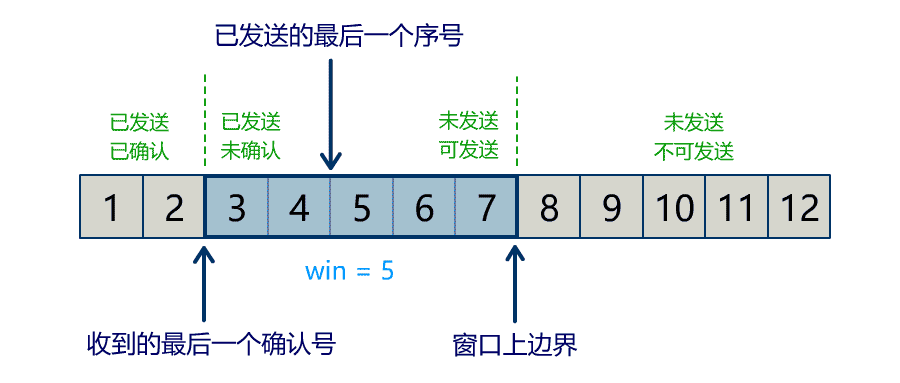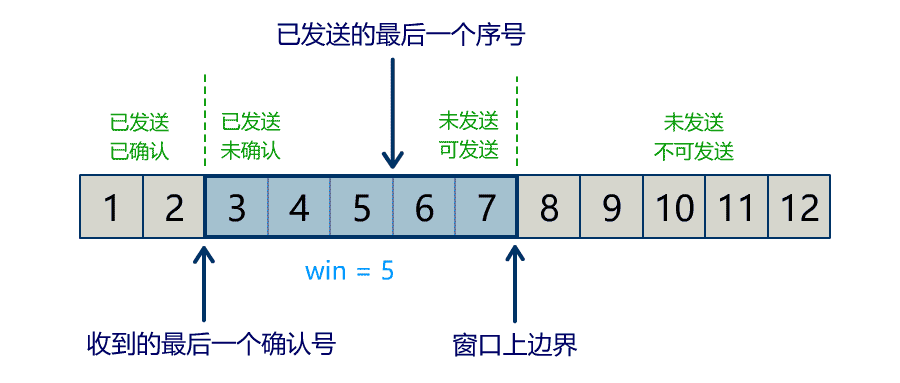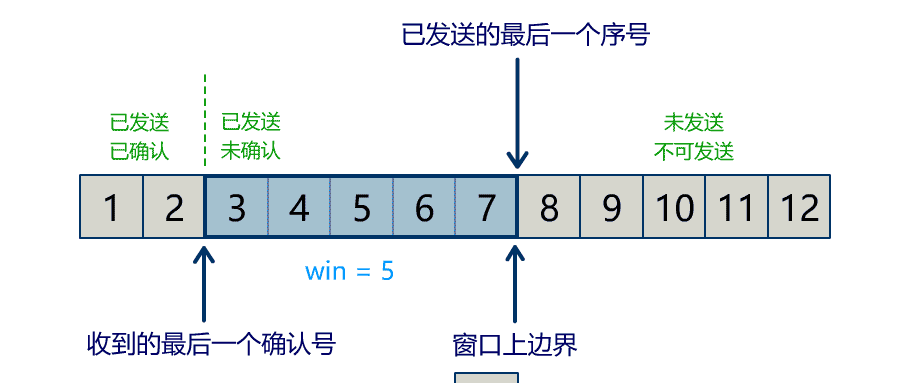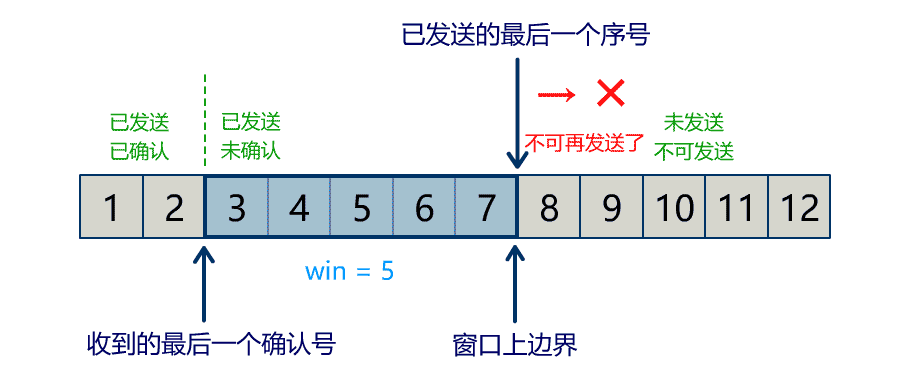
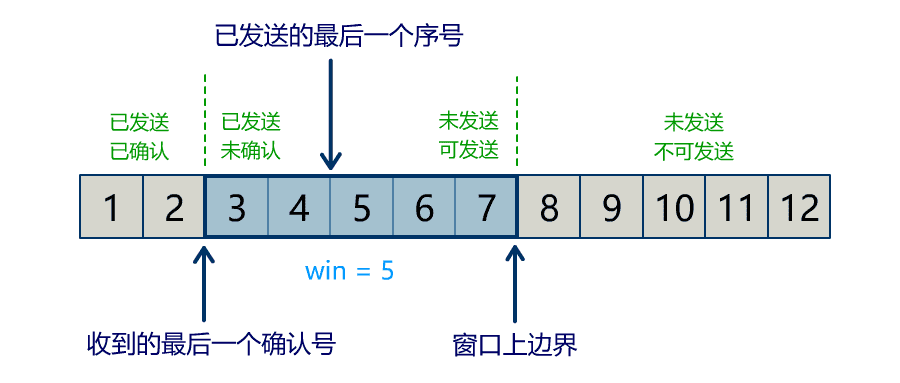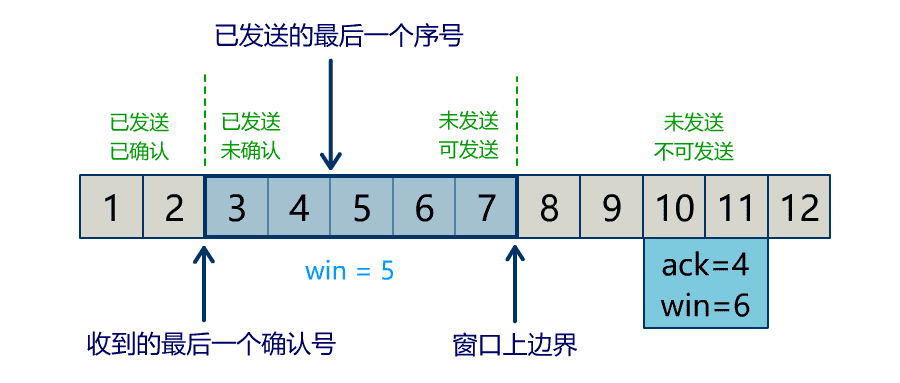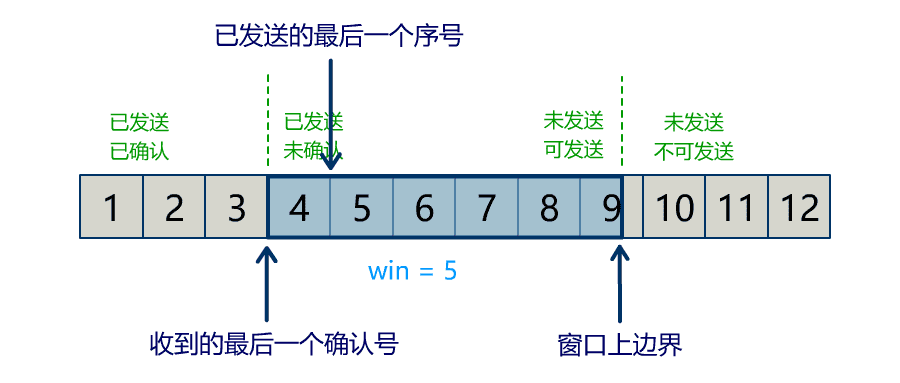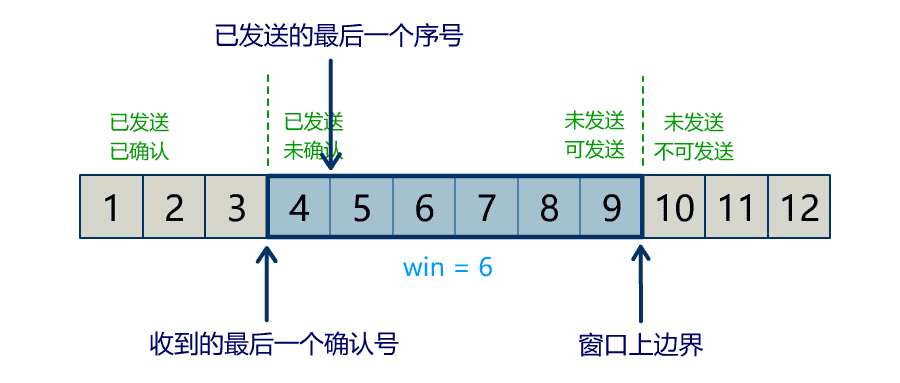
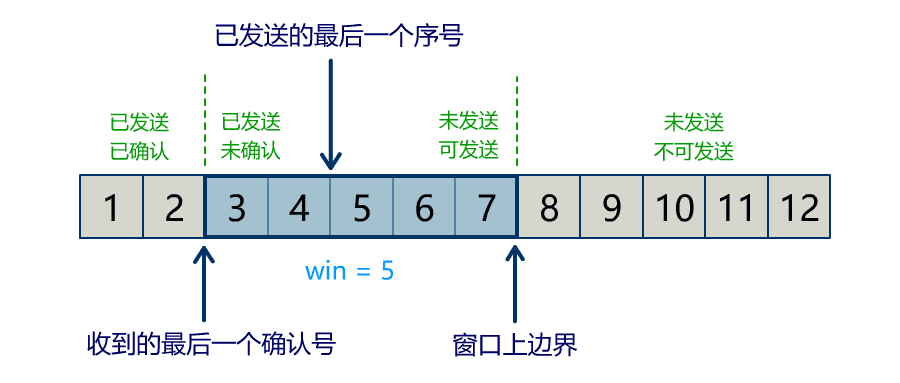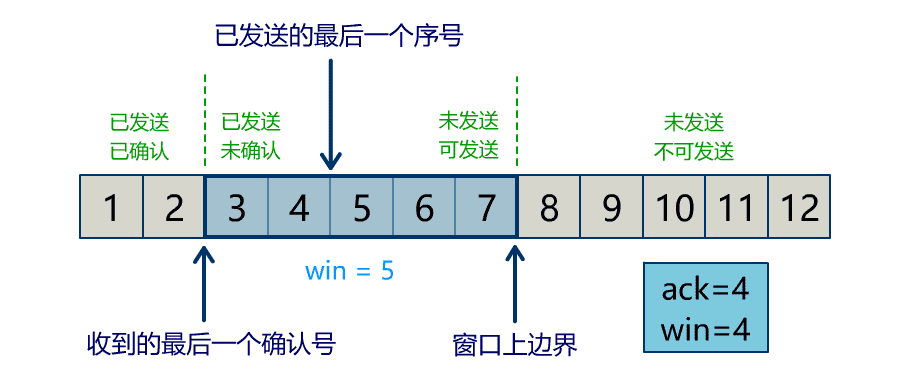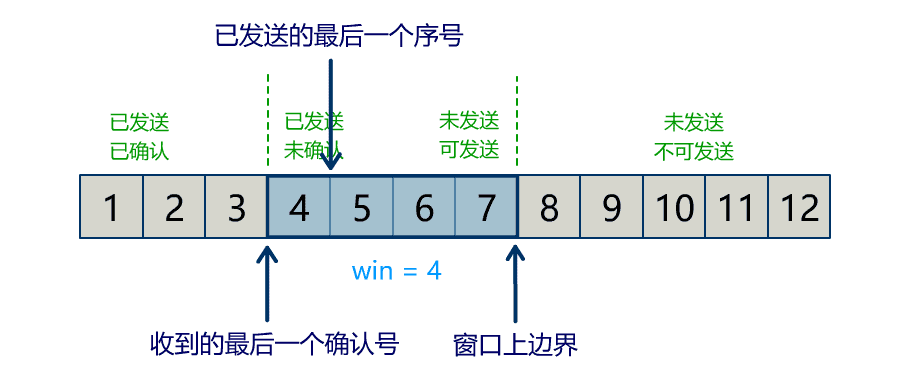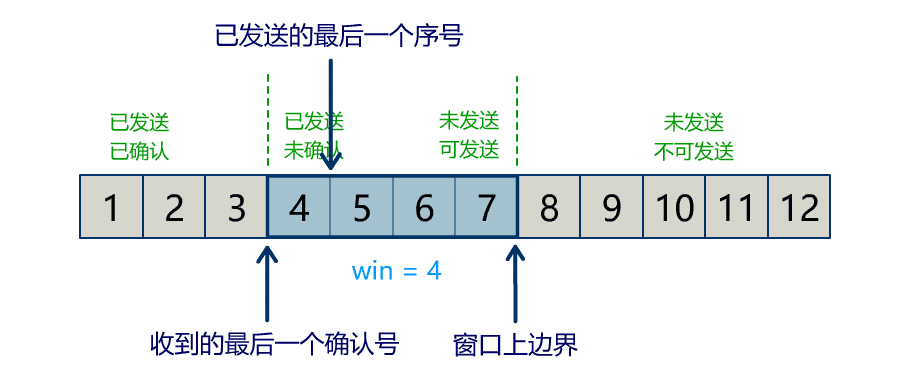
流量问题
拥塞问题
连接问题
A:我准备好了(SYN) B:我知道了(ACK),我也准备好了(SYN) A:我知道了(ACK)
A:再见,我要关闭了(FIN) B:我知道了(ACK) 给 B 一段时间把自己的事情处理完... B:再见,我要关闭了(FIN) A:我知道了(ACK)
总结
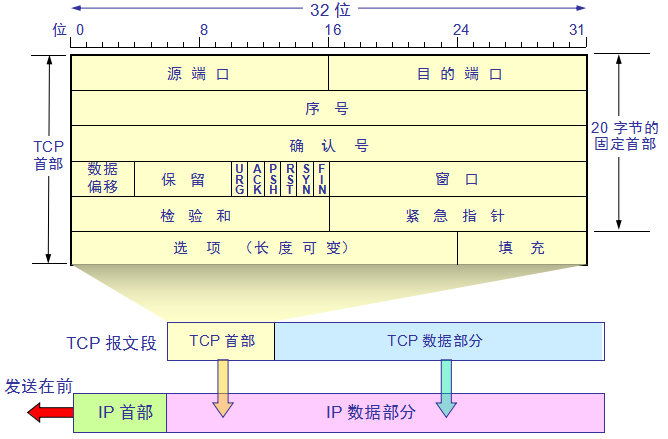
第一题:A 给 B 发送 "aaa" ,然后 B 给 A 回复一个简单的字符串 "success",并将此过程抓包。 第二题:A 给 B 发送 "aaaaaa ... a" 超过最大报文段大小,然后 B 给 A 回复一个简单的字符串 "success",并将此过程抓包。 三次握手阶段 A -> B [SYN] Seq=0 Win=64240 Len=0 MSS=1460 WS=256 B - >A [SYN, ACK] Seq=0 Ack=1 Win=29200 Len=0 MSS=1424 WS=512 A -> B [ACK] Seq=1 Ack=1 Win=132352 Len=0 数据发送阶段 A -> B [ACK] Seq=1 Ack=1 Win=132352 Len=1424 A -> B [ACK] Seq=1425 Ack=1 Win=132352 Len=1424 A -> B [PSH, ACK] Seq=2849 Ack=1 Win=132352 Len=1247 B -> A [ACK] Seq=1 Ack=1425 Win=32256 Len=0 B -> A [ACK] Seq=1 Ack=2849 Win=35328 Len=0 B -> A [ACK] Seq=1 Ack=4096 Win=37888 Len=0 B -> A [PSH, ACK] Seq=1 Ack=4096 Win=37888 Len=7 四次挥手阶段 B -> A [FIN, ACK] Seq=8 Ack=4096 Win=37888 Len=0 A -> B [ACK] Seq=4096 Ack=9 Win=132352 Len=0 A -> B [FIN, ACK] Seq=4096 Ack=9 Win=132352 Len=0(下面少复制了一行ACK,抱歉) 来源微信公众号:无聊的闪客 该文章在 2024/3/12 18:02:42 编辑过 |
关键字查询
相关文章
正在查询... 



|


 400 186 1886
400 186 1886