【SQLServer】使用SQL执行计划进行性能调优
当前位置:点晴教程→知识管理交流
→『 技术文档交流 』
SQL执行计划中会有许多迹象表明查询中可能存在不良性能点。例如,与整体查询成本相关的成本最高的最昂贵运算符是查询性能故障排除的良好起点。此外,后面跟着细箭头的粗箭头表示正在处理大量记录并从一个运算符流向另一个运算符以检索少量记录,这也可能是缺少索引或性能问题的标志。 在了解了本系列中讨论的每个计划运算符的作用之后,你可以识别出由于额外开销而降低查询性能的额外运算符。此外,用于扫描整个表或索引的Scan运算符表明大多数情况下存在缺少索引、索引使用不当或查询不包含过滤条件。执行计划中查询中性能问题的另一个标志是执行计划警告。这些消息用于警告查询的不同问题以进行故障排除,例如tempdb溢出问题、缺少索引或错误的基数估计。 要了解如何使用SQL执行计划来调整性能,让我们通过我们的实例演示。在开始第一个示例之前,我们将使用以下create TABLE语句创建两个新表:
然后使用ApexSQL Generate向每个表中插入100k条记录
调优简单的查询
调优查询性能的最佳方法是研究该查询的SQL执行计划。执行前面的查询:
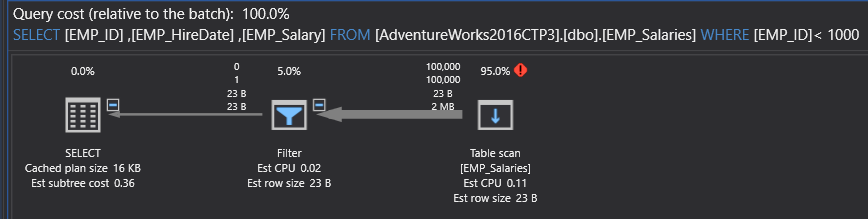
从生成的计划中可以清楚地看出,SQL Server引擎扫描所有表行(100K 记录)以检索请求的数据(1 条记录)。从三个迹象可以看出这一点: 使用ApexSQL Plan,可以检查查询的执行统计信息,例如该查询的读次数、持续时间和CPU成本,如下所示:
从计划中得出的三个标志将我们引向查询性能不佳的主要原因,即EMP_Salary表中没有索引,索引可以加快从该表中检索数据的过程。我们将继续使用下面的create INDEX语句在EMP_Salary表的EMP_ID列上创建索引:
…然后运行相同的语句。 从生成的执行计划中可以看出,SQL Server Engine会直接在创建的索引中寻找请求的数据,无需扫描整个底层表,Index Seek的成本降低到50%。此外,从Index Seek运算符流向下一个运算符的记录数明显减少,从箭头的粗细可以看出,如下图所示:
检查执行计划的统计信息,将看到行数如何减少到2,而持续时间和CPU成本可以忽略不计,如下所示:
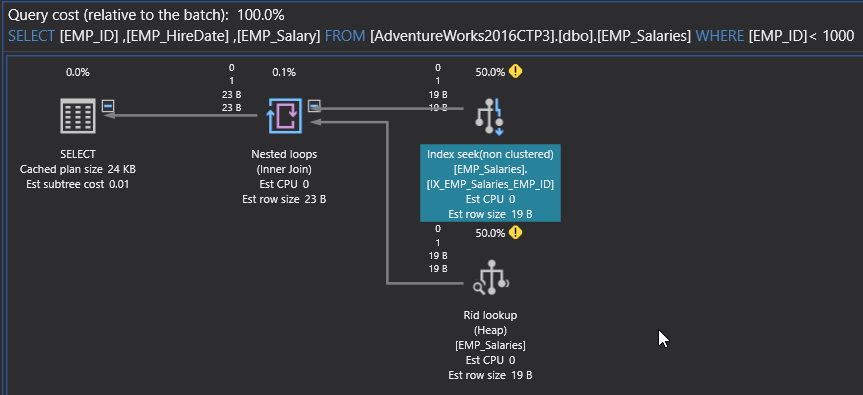
如果深入查看之前的计划,你会发现另一个性能问题的迹象,即额外昂贵的RID查找和嵌套循环运算符。SQL Server引擎使用非聚集索引检索EMP_ID列并返回基础表以检索其余列。这个问题可以通过创建一个覆盖索引来解决,它允许SQL Server引擎从该有序的索引中检索所有列,而无需检查基础表。 下面的create INDEX语句可用于为该查询创建覆盖索引:
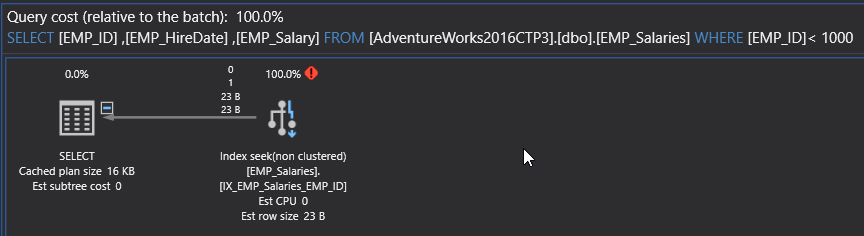
运行相同的select语句,将看到不再出现RID Lookup和Nested Loops运算符,因为SQL Server引擎在索引中找到了所有请求的数据,如下所示:
调优复杂查询 我们看到了SQL执行计划如何帮助我们调优简单查询的性能。它会以同样的方式帮助我们进行更复杂的查询的调优吗? 让我们删除在EMP_Salaries表上创建的索引:
假设我们需要调整以下查询的性能,该查询连接之前创建的两个EMP测试表,以检索员工的信息:
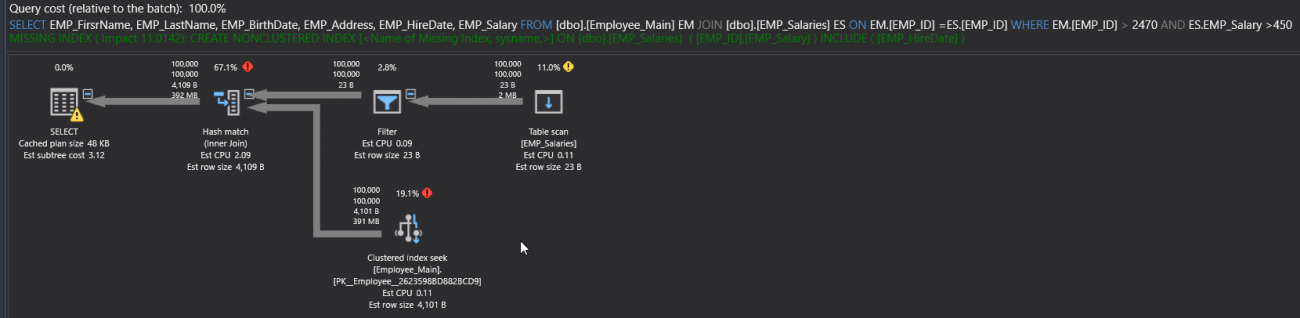
如果执行查询,你会从生成的计划中看到一些性能问题的迹象,比如Table Scan运算符,由于扫描了整个底层表;粗箭头,由于大量的行在运算符之间流动以及额外昂贵的运算符,例如Hash Match运算符,如下面的SQL执行计划所示:
查看查询的执行统计,会看到读取次数多,持续时间长,CPU消耗高,如下图:
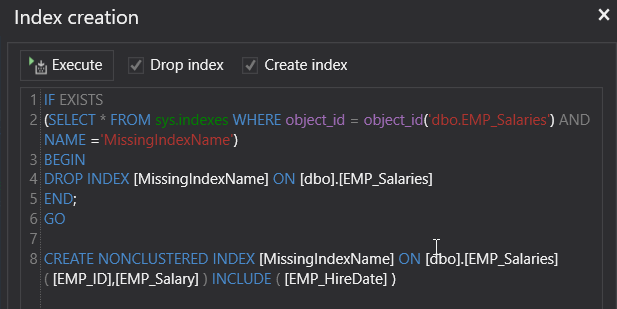
在执行计划的上半部分,将看到一条绿色的create INDEX语句,用于推荐的索引,这将提高查询的性能,如下所示:
如果我们创建了建议的索引,那么再次执行语句。生成的SQL执行计划将显示,Table Scan运算符更改为Index Seek运算符。但是箭头仍然是粗的,这是正常的行为,因为没有从粗箭头到细箭头的过渡,如下所示:
执行持续时间和CPU 成本的有点降低了,如下查询的执行统计所示:
可以通过更好的方式编写查询来实现查询性能的增强。例如,可以使用限制返回行数的TOP子句来减小箭头的粗细。另一方面,可以通过使用以下create INDEX语句在EMP_Salaries表上创建新索引来删除过滤器运算符:
而生成的执行计划,经过这些修改后,将是这样的:
该文章在 2023/11/27 11:52:27 编辑过 |
关键字查询
相关文章
正在查询... 



|


 400 186 1886
400 186 1886